Debrauwer, Laurent
[Lieu de publication non identifié] : Editions ENI, [2024]
1 ressource en ligne
Texte intégral en ligne




As we see LLMs churn out scads of code, folks have increasingly turned to Cognitive Debt as a metaphor for capturing how a team can lose understanding of what a system does. Margaret-Anne Storey thinks a good way of thinking about these problems is to consider three layers of system health:
- Technical debt lives in code. It accumulates when implementation decisions compromise future changeability. It limits how systems can change.
- Cognitive debt lives in people. It accumulates when shared understanding of the system erodes faster than it is replenished. It limits how teams can reason about change.
- Intent debt lives in artifacts. It accumulates when the goals and constraints that should guide the system are poorly captured or maintained. It limits whether the system continues to reflect what we meant to build and it limits how humans and AI agents can continue to evolve the system effectively.
While I’m getting a bit bemused by debt metaphor proliferation, this way of thinking does make a fair bit of sense. The article includes useful sections to diagnose and mitigate each kind of debt. The three interact with each other, and the article outlines some general activities teams should do to keep it all under control
❄ ❄
In the article she references a recent paper by Shaw and Nave at the Wharton School that adds LLMs to Kahneman’s two-system model of thinking.
Kahneman’s book, “Thinking Fast and Slow”, is one of my favorite books. Its central idea is that humans have two systems of cognition. System 1 (intuition) makes rapid decisions, often barely-consciously. System 2 (deliberation) is when we apply deliberate thinking to a problem. He observed that to save energy we default to intuition, and that sometimes gets us into trouble when we overlook things that we would have spotted had we applied deliberation to the problem.
Shaw and Nave consider AI as System 3
A consequence of System 3 is the introduction of cognitive surrender, characterized by uncritical reliance on externally generated artificial reasoning, bypassing System 2. Crucially, we distinguish cognitive surrender, marked by passive trust and uncritical evaluation of external information, from cognitive offloading, which involves strategic delegation of cognition during deliberation.
It’s a long paper, that does into detail on this “Tri-System theory of cognition” and reports on several experiments they’ve done to test how well this theory can predict behavior (at least within a lab).
❄ ❄ ❄ ❄ ❄
I’ve seen a few illustrations recently that use the symbols “< >” as part of an icon to illustrate code. That strikes me as rather odd, I can’t think of any programming language that uses “< >” to surround program elements. Why that and not, say, “{ }”?
Obviously the reason is that they are thinking of HTML (or maybe XML), which is even more obvious when they use “</>” in their icons. But programmers don’t program in HTML.
❄ ❄ ❄ ❄ ❄
Ajey Gore thinks about if coding agents make coding free, what becomes the expensive thing? His answer is verification.
What does “correct” mean for an ETA algorithm in Jakarta traffic versus Ho Chi Minh City? What does a “successful” driver allocation look like when you’re balancing earnings fairness, customer wait time, and fleet utilisation simultaneously? When hundreds of engineers are shipping into ~900 microservices around the clock, “correct” isn’t one definition — it’s thousands of definitions, all shifting, all context-dependent. These aren’t edge cases. They’re the entire job.
And they’re precisely the kind of judgment that agents cannot perform for you.
Increasingly I’m seeing a view that agents do really well when they have good, preferably automated, verification for their work. This encourages such things as Test Driven Development. That’s still a lot of verification to do, which suggests we should see more effort to find ways to make it easier for humans to comprehend larger ranges of tests.
While I agree with most of what Ajey writes here, I do have a quibble with his view of legacy migration. He thinks it’s a delusion that “agentic coding will finally crack legacy modernisation”. I agree with him that agentic coding is overrated in a legacy context, but I have seen compelling evidence that LLMs help a great deal in understanding what legacy code is doing.
The big consequence of Ajey’s assessment is that we’ll need to reorganize around verification rather than writing code:
If agents handle execution, the human job becomes designing verification systems, defining quality, and handling the ambiguous cases agents can’t resolve. Your org chart should reflect this. Practically, this means your Monday morning standup changes. Instead of “what did we ship?” the question becomes “what did we validate?” Instead of tracking output, you’re tracking whether the output was right. The team that used to have ten engineers building features now has three engineers and seven people defining acceptance criteria, designing test harnesses, and monitoring outcomes. That’s the reorganisation. It’s uncomfortable because it demotes the act of building and promotes the act of judging. Most engineering cultures resist this. The ones that don’t will win.
❄ ❄ ❄ ❄ ❄
One the questions comes up when we think of LLMs-as-programmers is whether there is a future for source code. David Cassel on The New Stack has an article summarizing several views of the future of code. Some folks are experimenting with entirely new languages built with the LLM in mind, others think that existing languages, especially strictly typed languages like TypeScript and Rust will be the best fit for LLMs. It’s an overview article, one that has lots of quotations, but not much analysis in itself - but it’s worth a read as a good overview of the discussion.
I’m interested to see how all this will play out. I do think there’s still a role for humans to work with LLMs to build useful abstractions in which to talk about what the code does - essentially the DDD notion of Ubiquitous Language. Last year Unmesh and I talked about growing a language with LLMs. As Unmesh put it
Programming isn’t just typing coding syntax that computers can understand and execute; it’s shaping a solution. We slice the problem into focused pieces, bind related data and behaviour together, and—crucially—choose names that expose intent. Good names cut through complexity and turn code into a schematic everyone can follow. The most creative act is this continual weaving of names that reveal the structure of the solution that maps clearly to the problem we are trying to solve.
In 1996 Brian Eno created Generative Music 1, an album distributed on 3.5″ floppy disk that ran on Windows 3.11. Now you can listen to a version of it without tracking down the requisite PC and rare disk!
The album was different every time you listened to it as it was generated in code from Tim and Pete Cole’s SSEYO Koan Pro music software and played through a Creative Labs AWE32 or SB32 sound card or a TDK MusicCard.

If you’re inspired to create your own generative music, the Koan software has evolved into Wotja and is available for free on most platforms.
Lots more info here on the ever-awesome Peter Kirn’s CDM blog.
It’s been 10 years since I began writing the Microservice Architecture pattern language. Here’s a presentation that I gave at the recent Pattern Languages of Programs, People & Practices (PLoP 2024) conference on the evolution of the pattern language.
Patterns have played a major role in my thinking for decades and it was great to discuss the evolution of the pattern language with the patterns community. Since the audience came from a variety of fields - not just software development - I started by explaining the core concepts of software architecture and architectural styles, highlighting the importance of non-functional requirements like runtime behavior and ease of development. I then introduced the Microservice Architecture, an architectural style that enables fast flow – a way of working that allows teams to deliver continuous streams of small changes, fostering rapid feedback and learning.
The pattern language, which I started developing back in 2014, provides guidance to developers navigating the complexities of implementing a Microservice Architecture, helping them decide whether it is a good fit for their application, and address the various challenges that arise.
A key part of the presentation discussed the evolution of the pattern language over the years. It wasn’t a carefully planned process; it grew organically based on practical experiences and feedback.
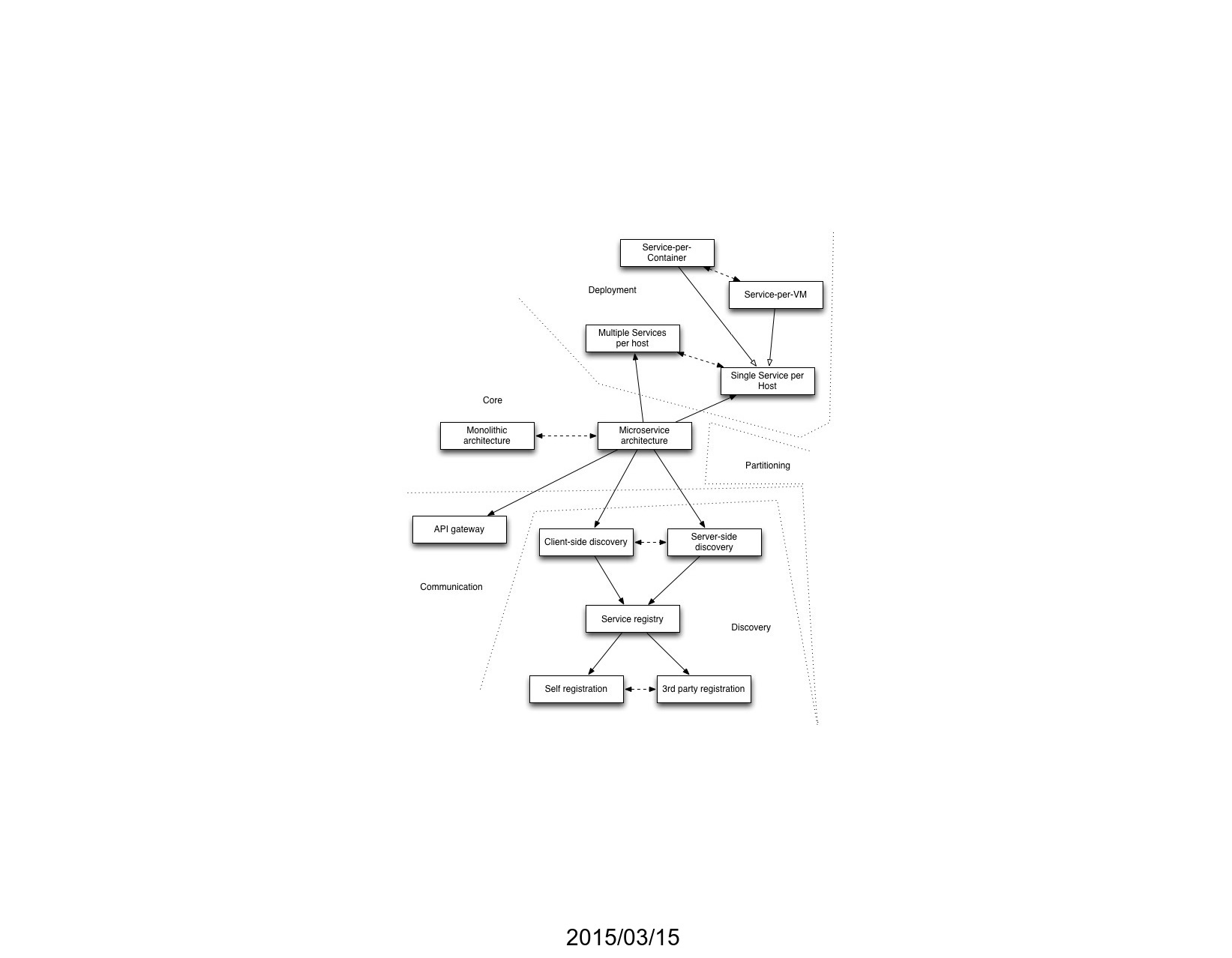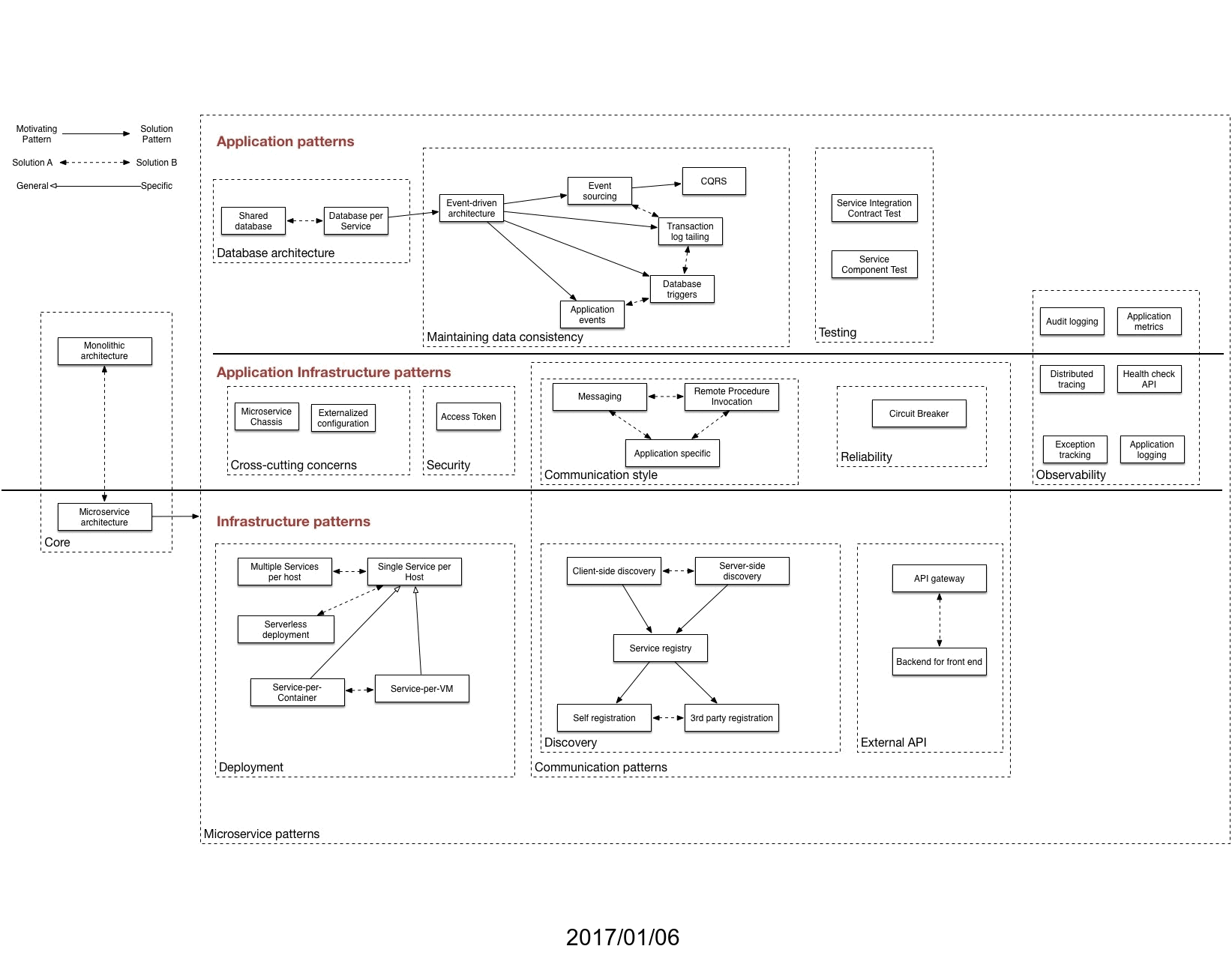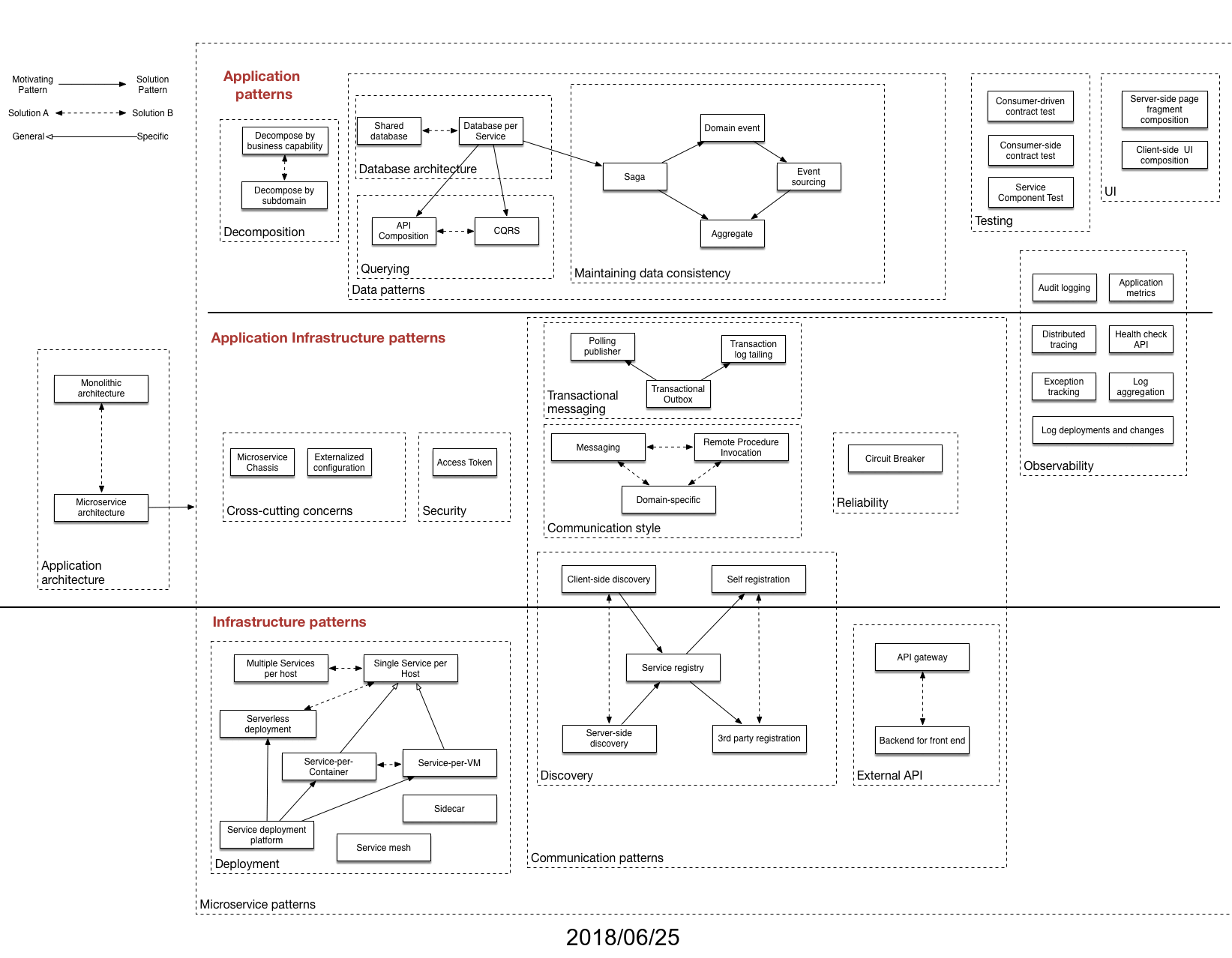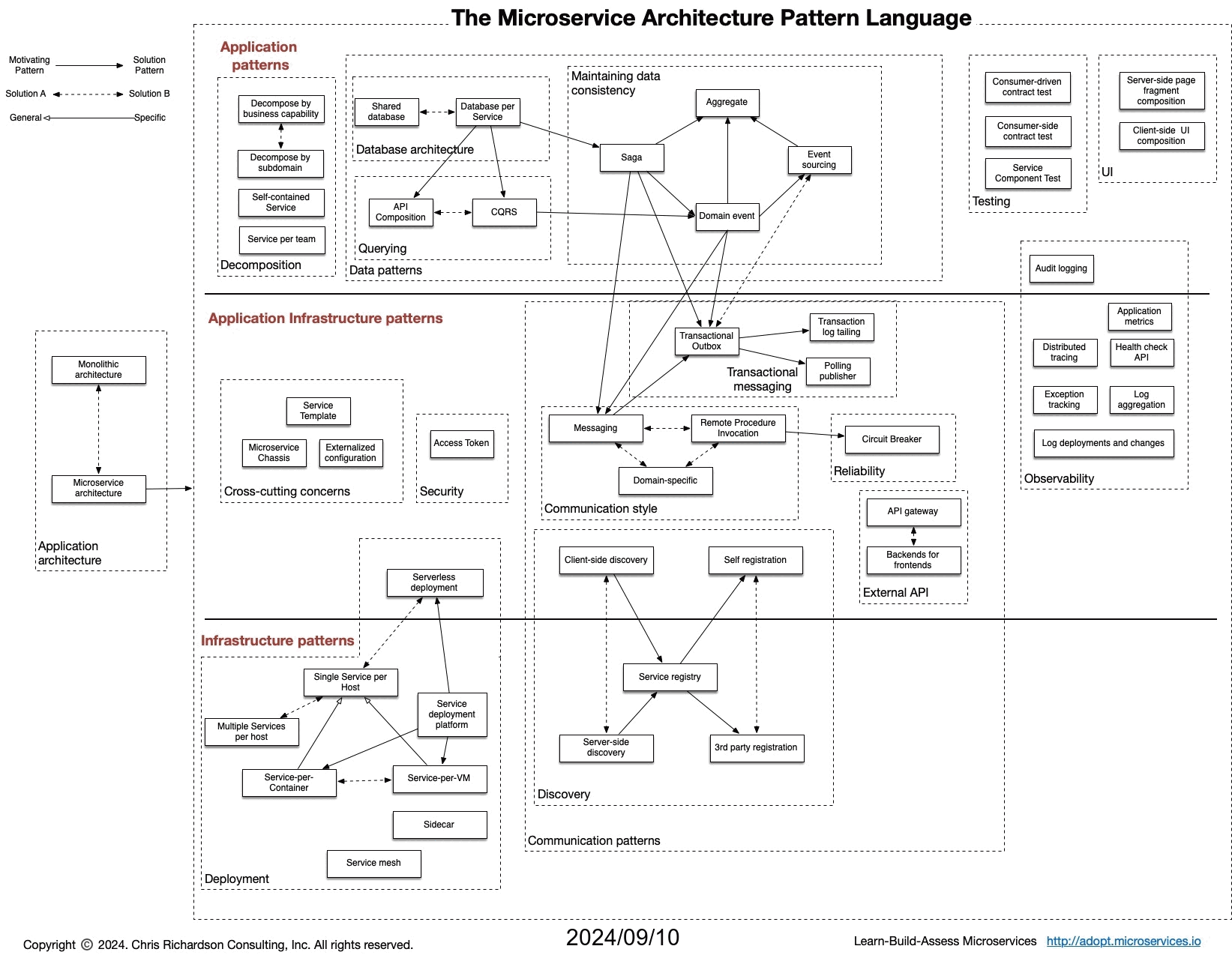
I shared how I introduced the anti-patterns of microservice adoption, based on my observations, to help developers avoid common pitfalls. I also explained how key definitions within the pattern language were refined over time, leading to a clearer understanding of core concepts like loosely coupled and independent deployable services.
One of the more interesting developments of the pattern language was the introduction of dark energy and dark matter as metaphors for the forces that shape architectural decisions. Dark energy, representing forces pushing for smaller, more independent services, resulting in improved team autonomy and agility. Dark matter, on the other hand, represents the forces that encourage larger services, even a monolith, in order to avoid the downsides of a distributed architecture. These opposing forces create a constant tension in architectural design and architects must carefully balance them.
It’s important to remember that the context plays a crucial role in determining the strength and relevance of these forces. The size and structure of the development team, the nature of the application, and the capabilities of the deployment pipeline all influence the architectural choices.
Moving beyond simply applying predefined patterns, I introduced Assemblage, which is a deliberative process for designing a microservice architecture.
Looking ahead, I outlined several improvements for the pattern language. These include refining the terminology used to describe the roles within a pattern’s solution, simplifying the treatment of database architecture patterns, and exploring the relationship between patterns and Team Topologies.
While the focus is often on microservices, I also emphasized that monolithic architectures are still valid and valuable for many applications contexts. Applying principles like modularity and minimizing build-time coupling can even help create well-designed, modular monoliths that are easier to maintain and evolve.
The presentation concluded by emphasizing the continued relevance of the pattern language, the need for ongoing adaptation to keep pace with new knowledge and changes in the technology landscape, and the importance of using precise language to effectively communicate architectural concepts.
I’m available to help your organization improve agility and competitiveness through better software architecture: training workshops, architecture reviews, etc.

Embedded systems have become a cornerstone of modern technology, powering everything from IoT devices to automotive control systems. These specialized systems rely on software that is lightweight, efficient, and highly optimized for specific hardware configurations. At the heart of this software stack lies the Linux kernel, which is widely used in embedded devices due to its flexibility, robustness, and open-source nature.
However, the generic Linux kernel is often bloated with unnecessary drivers, modules, and features that are irrelevant for embedded applications. For developers working on embedded systems, building a custom Linux kernel is not only a means to optimize performance but also a way to reduce the system's resource consumption, improve security, and enhance hardware compatibility.
In this article, we will guide you through the intricate process of building a custom Linux kernel for embedded systems. We will explore the reasons for kernel customization, the necessary prerequisites, step-by-step instructions for configuring, compiling, and deploying the kernel, and finally, best practices to ensure stability and performance in production environments.
One of the key reasons to build a custom Linux kernel for an embedded system is performance. The default kernel comes packed with features that are designed to work across a wide range of hardware platforms, but these general-purpose features are often unnecessary in embedded applications. By removing unused drivers and modules, you can significantly improve system performance, reduce boot times, and optimize resource usage. This allows the embedded system to run faster, with fewer interruptions and lower power consumption, which is crucial for devices with limited computational power or battery life.
For instance, an IoT device running on an ARM-based processor doesn't need support for high-performance networking protocols or advanced graphical interfaces. Customizing the kernel ensures that only the essential features are included, thus reducing overhead.
Reduced Resource ConsumptionEmbedded systems often operate with limited memory, storage, and CPU power. A lean, stripped-down kernel can minimize memory usage, helping the device operate more efficiently. By eliminating unnecessary features such as unused file systems, debugging symbols, and kernel-level services, you can conserve valuable system resources. This is especially important for real-time embedded systems, where even small inefficiencies can result in delayed responses or missed deadlines.
